Содержание
Классификация и размеры дорожных знаков
Классификация и размеры дорожных знаков 16.05.2017 10:53
Правительство постоянно принимает меры, чтобы улучшить работу дорожной полиции, однако требования закона инспектора выполняют далеко не всегда. Случаи, когда водителя наказывают за нарушения предписаний дорожных знаков, которые плохо видны или установлены без соблюдения ГОСТов, не редкость. Но если водитель знаком с общими стандартами организации дорожного движения, в подобных ситуациях ему, скорее всего, удастся избежать наказания.
ГОСТ Р 52289-2004
Вступил в силу после приказа ФАТРИМ 15.12.2004. Регламентирует размеры дорожных знаков и указателей, а также правила их монтажа и применения. С тех пор в этот ГОСТ вносились изменения. Ознакомиться с ними можно в ежегодном издании «Национальные стандарты» либо на официальном сайте уполномоченной организации.
В Мингосстате за основу приняты некоторые нормативы:
- Система организации дорожного движения и правила использования указателей, светофоров, разметки.

- Классификация измерительных устройств.
- Система единых световых измерений.
- Соответствие ЛКМ и методика определения стойкости к температурным перепадам, светостойкости и адгезии.
- Требования к старению и защите от коррозии, а также технология измерений на устойчивость к разным климатическим факторам.
В связи с возможными изменениями в ГОСТе следует обращать внимание на вышеперечисленные нормативы. Это также относится к месту установки и размерам каждого знака – даже незначительное отклонение от ГОСТа может сыграть роль при оспаривании выписанного протокола.
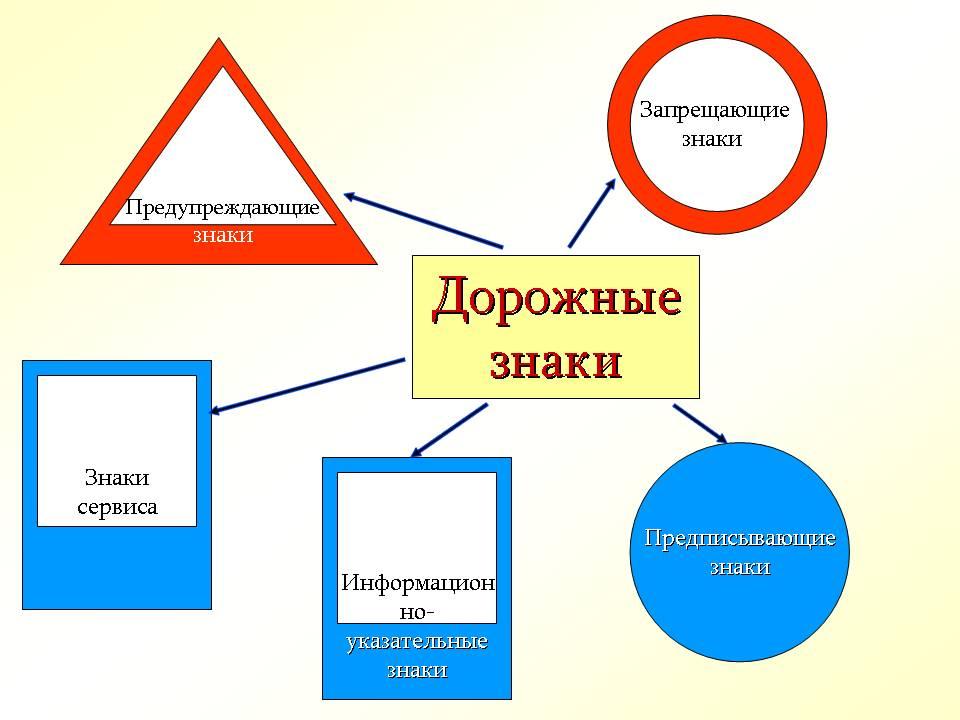
Классификация средств организации движения транспорта
Все средства по организации транспортного движения ГОСТы сегодня подразделяют на несколько типов:
- приоритетные,
- запрещающие,
- предписывающие,
- особых предписаний,
- предупреждающие,
- информационные,
- сервисные,
- дополнительной информации.

В законе прописан комплекс правил по дорожным знакам, выполненных по индивидуальным проектам. Цель их создания – указание определенных путей перемещения для посетителей. На таких указателях чаще всего ссылаются на следующие объекты:
- исторические памятники,
- спортивные объекты,
- элементы дорог и магистралей,
- малые административные районы,
- туристические маршруты,
- объекты сервиса,
- ландшафтные и географические пункты.
На подобных информационных указателях фон может иметь разный цвет, который зависит от места установки знака:
- на дорогах населенных пунктов – белый,
- за пределами населенных пунктов – синий,
- на магистралях и автобанах – зеленый.
Размеры знаков согласно ГОСТ Р 52289-2004
Информационные указатели должны быть установлены на всех дорогах, от проселочных до федеральных трасс. Для них предусмотрено четыре размера:
- 1 – малый.
- 2 – нормальный.
- 3 – большой.
- 4 – очень большой.

Каждый из размеров предполагает, что знак будет монтироваться в соответствии с местными условиями и требованиями ГОСТа. Указатели, которые размещаются за границами населенных пунктов:
- малые – на шоссе с одной полосой;
- нормальные – на 2-полосных и 3-полосных трассах;
- большие – на скоростных многополосных автомагистралях.
Знаки, размещаемые для организации дорожного движения на территории населенных пунктов:
- малые – на дорогах местного значения;
- нормальные – на главных улицах;
- большие – на скоростных магистралях с 4-мя и более полосами движения.
Знаки типоразмера «очень большие» предназначены для установки на опасных участках и при выполнении ремонтных работ. Они ставятся как в городе, так и за его пределами.
Размеры указателей определяет их геометрия и назначение:
- Прямоугольная с длинной стороной 400-1350 мм и короткой 200-900 мм.
- Квадратная со сторонами 350-1200 мм.
- Треугольная с длиной каждой из сторон 700-1500 мм.
- Круглая с диаметром 600-1200 мм.

Особую форму имеет знак СТОП – это правильный восьмиугольник с длиной каждой стороны 600-1200 мм.
Радиус закругления углов на дорожных знаках прямоугольной, треугольной и квадратной формы составляет 20 или 45 мм, в зависимости от их общего размера. Также на указателях предусмотрена наружная кайма, отклонения в размерах которой согласно ГОСТу не должны превышать 2 мм. Для закруглений допустима погрешность 5 мм.
На что следует обратить особое внимание?
Дорожные знаки должны непременно находиться в пределах видимости каждого водителя, поскольку предназначены именно для них. За 100 метров до указателя водитель должен на 100% прочитать его информацию.
Снаружи знаки должны быть покрыты светоотражающим слоем, который улучшает восприятие надписей и символов в темное время. Если такое покрытие имеет даже незначительный дефект, этот факт сразу отменяет действие знака.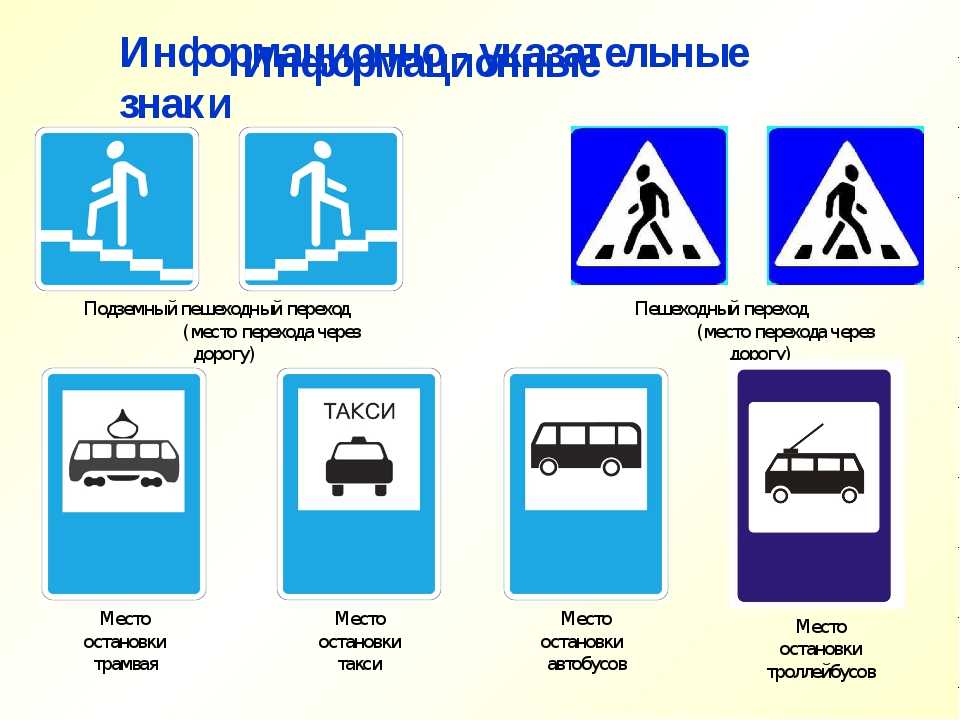 Поверхность указателя также должна быть максимально чистой, чтобы грязь не мешала считывать информацию.
Поверхность указателя также должна быть максимально чистой, чтобы грязь не мешала считывать информацию.
Если инспектор утверждает, что вы нарушили предписанные знаком требования, лучше всего снять его на телефон или другое устройство. Видео лучше, чем фото. Такая запись объективно подтверждает, где находится указатель, в каком он состоянии, как хорошо его видно. Если получится, сделайте хотя бы одно фото инспектора рядом со знаком.
Классный час «Дорожные знаки и их классификация»
|
Сухотинский филиал МБОУ «Знаменская средняя общеобразовательная школа» Конспект классного часа на тему: «Дорожные знаки и их классификация», проведенного в 5 классе Классный руководитель: Толстенева С. |
 В.
В.Город, в котором
С тобой мы живем,
Можно по праву
Сравнить с букварем.
Азбукой улиц,
Проспектов, дорог,
Город дает нам
Все время урок.
Вот она, азбука –
Над головой:
Знаки развешены
Вдоль мостовой.
Азбуку города
Помни всегда,
Чтоб не случилась
С тобою беда.
Цели и задачи классного часа:
ознакомление учащихся с особенностями правил дорожного движения;
воспитание дорожной культуры школьников;
профилактика дорожно-транспортных происшествий среди младших подростков.
Ход классного часа
Дорожный знак — техническое средство безопасности дорожного движения, стандартизированный графический рисунок, устанавливаемый у дороги для сообщения определённой информации участникам дорожного движения.
Дорожные знаки и разметка помогают организовывать движение машин и людей, они облегчают работу водителей и помогают всем нам правильно ориентироваться в сложной обстановке на дорогах.
На этом дорожном языке с водителями и пешеходами разговаривают улицы всех стран мира. Когда человек учится читать, ему показывают буквы. Из букв складываются слова, из слов – предложения. У дорожного языка тоже есть буквы — знаки. Но их не нужно складывать в слова. Один знак, одна дорожная буква – это целая фраза, дорожный сигнал. Это сигналы-кружочки, треугольники, прямоугольники. Голубые, желтые, с красной каемочкой.
Когда вы идете по улице и смотрите по сторонам, то всюду видите дорожные знаки. Они разного цвета и разной формы. Как вы думаете, случайно ли это?
Дети: Дорожные знаки не случайны на улицах. Они подсказывают нам, как поступить в той или иной ситуации.
В давние времена, когда не было машин, по улицам ездили и ходили кому как захочется. А улицы современных больших городов заполнены легковыми и грузовыми автомобилями, автобусами, троллейбусами, трамваями. Беспорядок на улицах сделал бы жизнь трудной и опасной; машины создали бы заторы, наезжали на пешеходов, сталкивались. Не доставлялись бы вовремя товары в магазины, письма и газеты в наши дома. Врачи не поспевали бы к больным. Пожарные – на пожар…
Не доставлялись бы вовремя товары в магазины, письма и газеты в наши дома. Врачи не поспевали бы к больным. Пожарные – на пожар…
Чтобы беспорядка не было, составлены правила уличного движения – законы улиц и дорог. Водитель должен знать, что его ждет впереди на дороге. Об этом ему сообщают дорожные знаки. Они сделаны в виде простых рисунков, чтобы их можно было различить издалека и чтобы они были понятны и русскому, и иностранному туристу. Пешеходу также надо знать дорожные знаки, и тогда опасность ему будет не страшна.
Дорожные знаки нужны для поддержания порядка на дорогах. Одни знаки предупреждают об опасности, другие указывают направления движения, третьи вводят всякие запреты и ограничения и т.д.
ИСТОРИЯ ДОРОЖНЫХ ЗНАКОВ
Самые старые из всех дорожных знаков – указатели расстояний. Для того чтобы люди не сбились с дороги, ее помечали. Так, в Древнем Риме устанавливали каменные столбы – указатели, а у здания Форума в самом Риме стоял позолоченный камень, от которого велся счет расстояний всех главных дорог.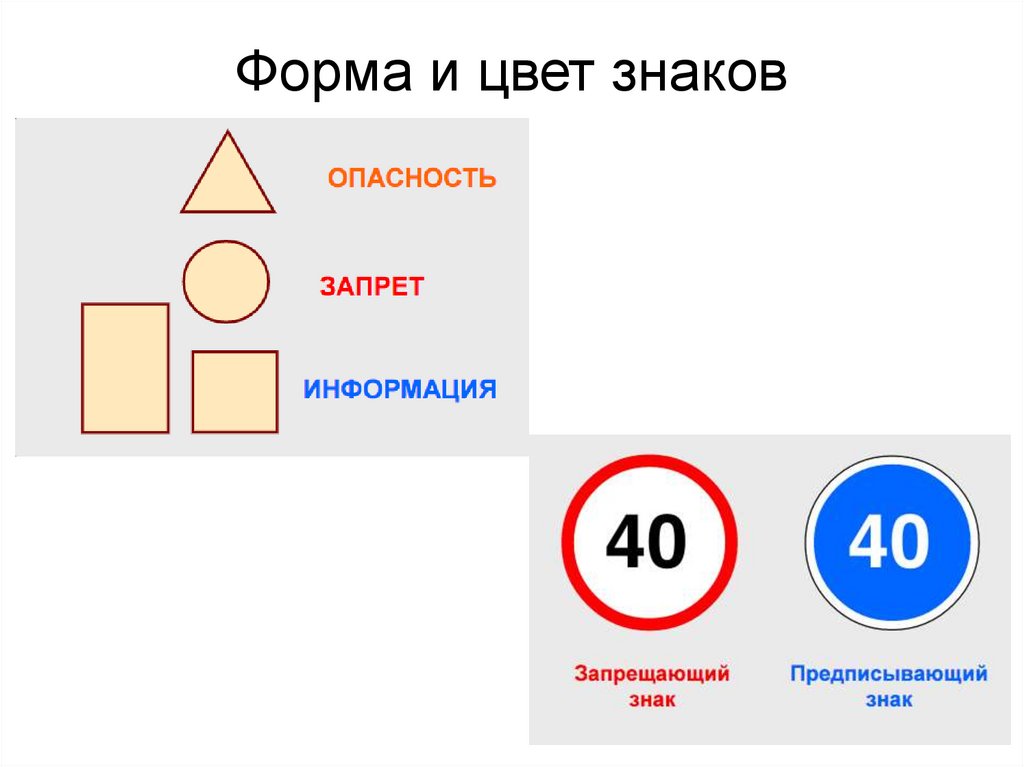
Наши предки – славяне – тоже заботились о путешественниках, старались помочь им выбрать правильное направление движения. В лесистых местах вдоль дорог устанавливали ветки из сучьев, делали затесы на стволах, а в степи вдоль дорог укладывали камни и ставили столбы. На перекрестках дорог устанавливали каменные или деревянные кресты, строили часовни.
Первые дорожные знаки на Руси возникли в XVII веке, при царе Алексее Михайловиче (1629–1676). Он построил себе дворец недалеко от Москвы, в селе Коломенское, куда часто приезжал на отдых и охоту. И вот между Москвой и Коломенским он велел поставить через каждую версту (старая мера длины, которая равнялась примерно 1,07 км) высокие нарядные столбы. Любому прохожему и проезжему они были видны издалека. Позже такие столбы поставили и на других дорогах. В народе их прозвали «коломенской верстой». При Петре I строительство дорог возросло. На большаках стали устанавливать верстовые столбы и раскрашивали их в цвет русского национального флага. Сегодня вместо верстовых столбов на дорогах установлены километровые указатели.
Сегодня вместо верстовых столбов на дорогах установлены километровые указатели.
Позднее стали устанавливать столбы на перекрестки и делать на них надписи, куда какая дорога ведет. Дороги, на которых ставили столбы, стали называться столбовыми, а на второстепенных дорогах столбов не было.
Но когда вместо саней, колясок, телег, запряженных лошадьми, потянулся непрерывный поток машин, оказалось, что одних указателей расстояний мало. Стало ясно, что нужны дорожные знаки.
Поначалу каждая страна имела свои дорожные знаки, их изготовляли дорожные органы. Но постепенно автомобильные сообщения между странами стали осуществляться довольно часто, возникла необходимость введения дорожных знаков международного значения. Попытка ввести единые международные знаки была предпринята в 1909 г., с этой целью в Париже собралась Международная конференция по дорожным знакам, на которой были приняты 4 международных знака.
Эти знаки имели символы, почти полностью соответствующие тем, которые применяются на современных знаках.
В 1968 г. на следующей конференции уже было введено 126 знаков. В 1978 г. принят новый государственный стандарт, который установил 7 групп дорожных знаков.
За прошедшие века дорожные знаки-указатели сильно видоизменились и стали разнообразными. Сейчас они окрашены в яркие цвета и видны издалека. Ночью некоторые из них светятся в лучах автомобильных фар – для этого на них нанесена специальная краска. Для удобства принято во всех странах мира использовать одинаковые знаки, чтобы любой пешеход или водитель, откуда бы он ни приехал, мог свободно по ним ориентироваться.
Все знаки по своему назначению разделены на 8 групп:
1) предупреждающие,
2) знаки приоритета,
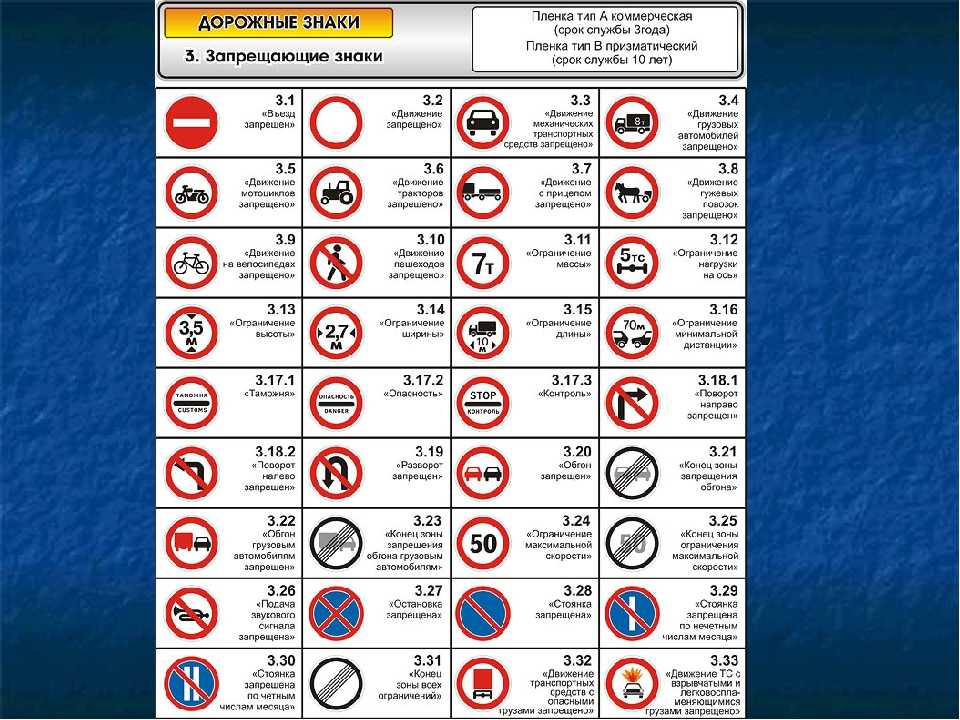
3) запрещающие,
4) предписывающие,
5) знаки особых предписаний,
6) информационно-указательные;
7) знаки сервиса,
8) знаки дополнительной информации (таблички).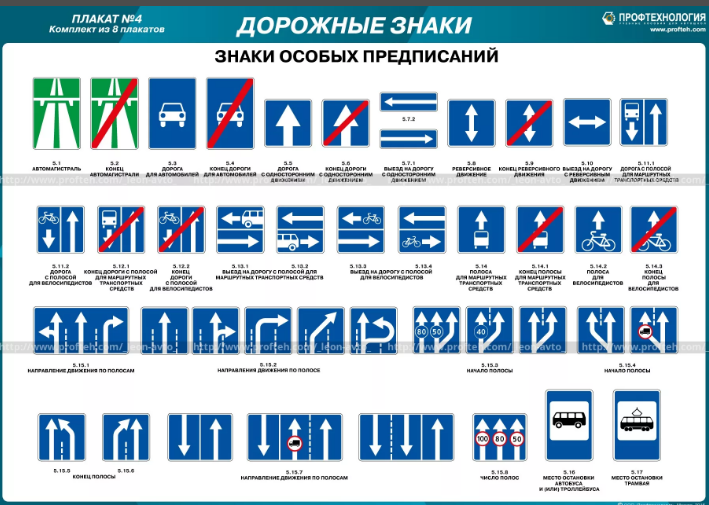
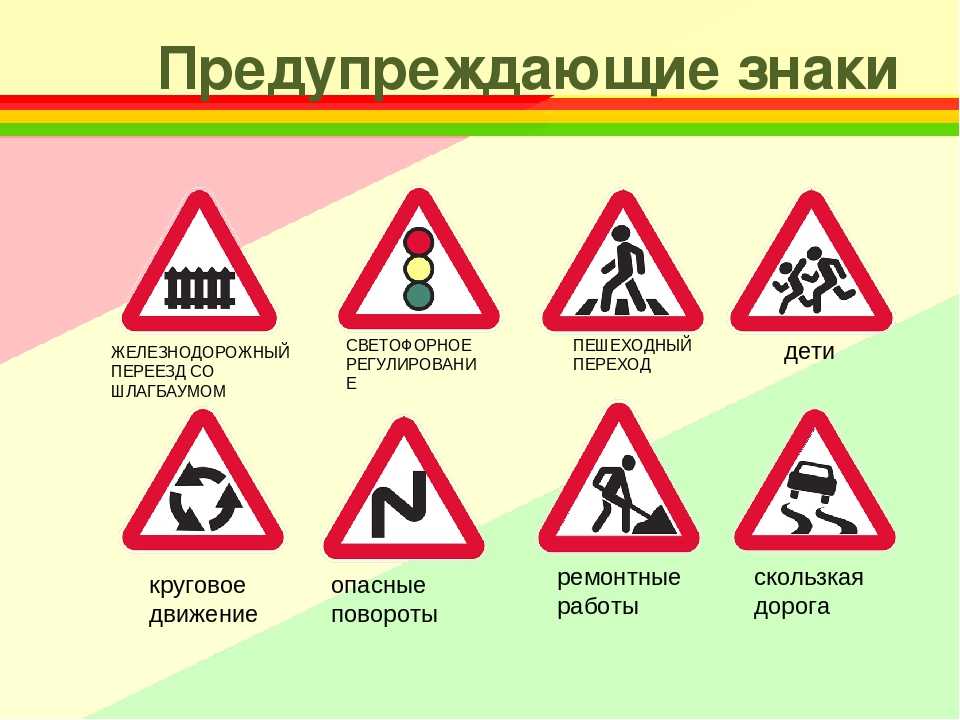
Предупреждающие знаки информируют водителей и пешеходов о том, что впереди есть опасный участок дороги. Такие знаки выполнены в виде треугольников с белым фоном и красной каймой. На белом фоне изображено то, что представляет опасность. Увидев такой знак, водитель должен проявить осторожность.
Знаки приоритета устанавливают первенство, очередность проезда разных участков дорог.
Запрещающие знаки вводят определенные ограничения для машин и пешеходов. Эти знаки (за исключением нескольких) выполнены в виде круга с белым фоном и красной каймой. Такие же знаки, только с черным окаймлением и перечеркнутые наискосок, отменяют ограничения запрещающих знаков.
Предписывающие знаки разрешают водителям двигаться в определенном направлении, с определенной скоростью, по определенным участкам дорог. Предписывающие знаки сделаны в виде голубого круга, в середине которого изображена разрешающая команда.
Знаки особых предписаний включают в себя надземный пешеходный переход, остановки общественного транспорта и т. д.
Информационные знаки, как правило, выполняются в виде прямоугольника с голубым фоном. Они сообщают об особенностях дорожной обстановки или о расположении на пути следования обозначенных на этих знаках объектов.
Знаки сервиса сообщают о расположении необходимых в пути объектов, таких, как пункт первой медицинской помощи, больница, телефон, места отдыха, туалет.
Знаки дополнительной информации (таблички) при необходимости уточняют, ограничивают или усиливают действие отдельных дорожных знаков.
Для лучшей видимости дорожные знаки устанавливаются на специальных колонках, столбах, мачтах справа по ходу движения, а если такие знаки могут быть не замечены водителем, то они повторяются над проезжей частью, на разделительной полосе или левой стороне дороги.
Одно из важных правил устанавливает, что запрещается снимать, повреждать или загораживать дорожные знаки. Виновные в этом несут ответственность за свои поступки.
Необходимо знать правило: если на дороге два противоречащих друг другу знака, один из которых – временный, на переносной стойке, а второй – постоянный, то руководствоваться надо временным знаком.
А теперь познакомимся с некоторыми из дорожных знаков.
ПРЕДУПРЕЖДАЮЩИЕ ЗНАКИ
Всего знаков в виде треугольников, окрашенных в белый цвет и обведенных красной каймой, около сорока.
Это предупреждающие знаки, которые говорят о том, что на пути водителя или пешехода будет очень опасное место.
Например, нарисованный в треугольнике паровоз предупреждает о том, что через несколько сотен или десятков метров «Железнодорожный переезд без шлагбаума».
Знак «Дети» вывешивают у школ, детских садов, оздоровительных детских лагерей и других детских учреждений. Этот знак предупреждает всех водителей, что здесь надо ехать осторожно.
Этот знак предупреждает всех водителей, что здесь надо ехать осторожно.
Также к осторожности водителей призывает знак треугольной формы, который называется: «Пешеходный переход». Этот знак устанавливается за несколько десятков метров до того места на дороге, где пешеходы переходят проезжую часть. Водитель должен сбросить скорость перед переходом, ехать медленнее.
Знак, на котором нарисован человек с лопатой, называется «Дорожные работы». Его устанавливают в местах, где ремонтируют дорогу.
ЗАПРЕЩАЮЩИЕ ЗНАКИ
Белые круги, обведенные красной каймой, – как правило, запрещающие знаки. Им обязаны подчиняться все. В центре таких знаков либо рисунки, либо цифры. Только некоторые из них окрашены иначе – в красный или синий цвет.
Например, красный круг с белой полосой, похожей на кирпич, называется «Въезд запрещен» и означает «Стоп! Дальше ехать нельзя!». Его вывешивают посредине улицы или укрепляют на особых столбах. У этого знака водитель автомобиля, мотоциклист или велосипедист должны остановиться и найти проезд по другой улице.
Его вывешивают посредине улицы или укрепляют на особых столбах. У этого знака водитель автомобиля, мотоциклист или велосипедист должны остановиться и найти проезд по другой улице.
Чистый белый круг с красной каймой без рисунка означает «Движение запрещено». Если установлен такой знак, то ни шофер, ни мотоциклист, ни велосипедист не имеют права проехать по этой улице. Но есть исключение: они могут при крайней необходимости заехать на эту улицу, если им надо подвезти товар к магазину или въехать во двор близко расположенного дома.
Проезд велосипедисту запрещен там, где висит круглый знак с красной каймой и с изображением велосипеда в центре. Придется либо искать другую дорогу, либо сойти с велосипеда и везти его, держа руками. Обычно этот знак устанавливается перед очень оживленными улицами и при въезде на автомагистраль, на которой движение для велосипедистов опасно.
ПРЕДПИСЫВАЮЩИЕ ЗНАКИ
Существует семнадцать предписывающих знаков, они выполнены в виде синих кругов.
Знаки в виде синих кругов, на которых нарисованы белые стрелки, указывают направление движения по этой улице. Например, знак, стрелка на котором смотрит вправо, указывает, что здесь ехать надо только направо. Знак со стрелкой влево означает, что надо поворачивать налево. Знаке, на котором изображена стрелка, смотрящая вверх, указывает, что здесь можно ехать только прямо.
Знак, на котором нарисованы три стрелки, составляющие круг, показывает, что прямо ехать нельзя, движение разрешено только по кругу (круговое движение).
Если на знаке изображена легковая машина, значит, по этой улице разрешается движение только легковых автомобилей.
Синий знак с нарисованным белой краской велосипедистом обозначает велосипедную дорожку. Там, где он висит, смело можно ехать на любых велосипедах, даже на таких, которые снабжены моторчиком.
ЗНАКИ ОСОБЫХ ПРЕДПИСАНИЙ
К этой группе относятся более пятидесяти знаков. Знаки особых предписаний вводят или отменяют определенные режимы движения.
Знаки особых предписаний вводят или отменяют определенные режимы движения.
Самый главный для нас – это, конечно, «Пешеходный переход» (надземный), или «зебра». «Место остановки автобуса и (или) троллейбуса», «Место остановки трамвая», «Автомагистраль», «Жилая зона», «Пешеходная зона» тоже входят в эту группу.
ИНФОРМАЦИОННЫЕ ЗНАКИ
Около тридцати знаков этой группы информируют об определенном режиме движения, расположении населенных пунктов и других объектов.
К знакам информационной группы относятся знаки, обозначающие место стоянки, рекомендованную скорость движения, тупик, предварительный указатель направления движения, остановку общественного транспорта – автобуса, троллейбуса, трамвая, такси.
Также эти знаки информируют о подземном и надземном пешеходных переходах, наименовании населенных пунктов.
ЗНАКИ СЕРВИСА
Восемнадцать прямоугольников, окрашенных в синий цвет – это знаки, которые подсказывают водителю, где можно найти место для отдыха, для мойки или ремонта автомобиля.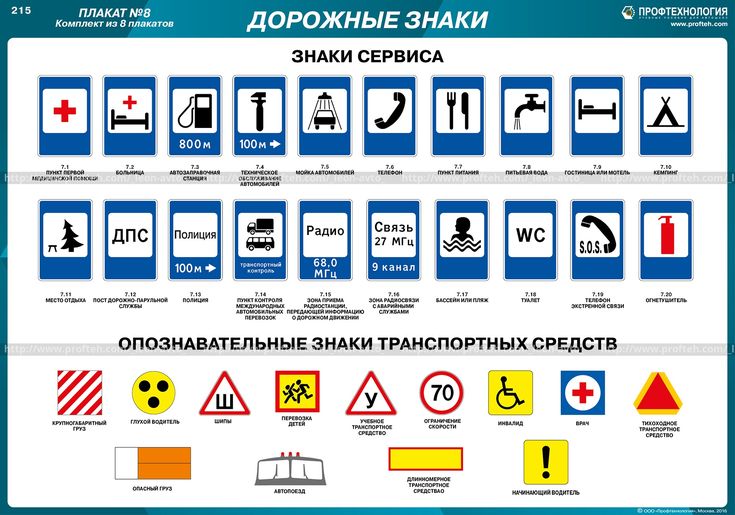
Например, знак с изображением вилки и ножа означает, что недалеко находится закусочная или придорожное кафе.
Знак с изображением кровати указывает, что у дороги есть гостиница или мотель.
Красный крест на знаке указывает, где размещается пункт медицинской помощи.
Знак, на котором нарисован слесарный ключ, важен водителям, у которых по дороге сломался автомобиль. Этот знак помогает найти авторемонтную мастерскую.
Знак с изображением бензозаправочной колонки сообщает, какое расстояние осталось до автозаправки.
Знаки важные, дорожные –
Компас взрослых и ребят.
Дети! Будьте осторожны!
Знайте, что нельзя, что можно!
Выполняйте непреложно
Все, что знаки говорят!
7
Как построить CNN для дорожных знаков
Фото J.C. Jiménez на Unsplash
Обучение использованию возможностей CNN
Каждый год автопроизводители добавляют в свои автопарки более передовых систем помощи водителю (ADAS). К ним относятся адаптивный круиз-контроль (ACC), предупреждение о лобовом столкновении (FCW), автоматическая парковка и многое другое. Одно исследование показало, что ADAS может предотвратить до 28% всех аварий в Соединенных Штатах. Эта технология будет только совершенствоваться и в конечном итоге превратится в полностью автономные автомобили пятого уровня.
К ним относятся адаптивный круиз-контроль (ACC), предупреждение о лобовом столкновении (FCW), автоматическая парковка и многое другое. Одно исследование показало, что ADAS может предотвратить до 28% всех аварий в Соединенных Штатах. Эта технология будет только совершенствоваться и в конечном итоге превратится в полностью автономные автомобили пятого уровня.
Чтобы автомобиль полностью управлял собой, он должен понимать окружающую среду. Сюда входят другие транспортные средства, пешеходы и дорожные знаки .
Дорожные знаки дают нам важную информацию о законах, предупреждают нас об опасных условиях и направляют нас к желаемому месту назначения. Если автомобиль не различает символы, цвета и формы, многие люди могут серьезно пострадать.
То, как автомобиль видит дорогу, отличается от того, как мы ее воспринимаем. Мы все можем мгновенно отличить дорожные знаки от различных дорожных ситуаций. При передаче изображений на компьютер они видят только единицы и нули. Это означает, что нам нужно научить машину учиться, как люди, или, по крайней мере, распознавать знаки, как мы.
Это означает, что нам нужно научить машину учиться, как люди, или, по крайней мере, распознавать знаки, как мы.
Чтобы решить эту проблему, я попытался построить свою собственную сверточную нейронную сеть (CNN) для классификации дорожных знаков. В этом процессе есть три основных этапа: предварительная обработка изображений , построение сверточной нейронной сети и вывод прогноза .
На этапе предварительной обработки изображения импортируются из репозитория Bitbucket «german-traffic-signs». Он содержит набор данных из помеченных изображений , что позволит нам построить модель обучения под наблюдением. Этот репозиторий можно клонировать в записную книжку Google Colab, что упрощает импорт набора данных и начало кодирования.
Теперь, чтобы использовать этот набор данных, изображения будут обработаны функцией оттенков серого и выравнивания .
Оттенки серого
В настоящее время изображения из репозитория трехмерные . Это связано с тем, что цветные изображения имеют три цветовых канала — красный, зеленый и синий (RGB), которые накладываются друг на друга, чтобы придать им яркие цвета.
Это связано с тем, что цветные изображения имеют три цветовых канала — красный, зеленый и синий (RGB), которые накладываются друг на друга, чтобы придать им яркие цвета.
Для этой модели машинного обучения не нужны три слоя изображений, нужны только признаки знаков. Таким образом, передача изображений набора данных через функцию оттенков серого очищает наши данные и фильтрует только важную информацию, а также уменьшает изображения до одного измерения.
Разбивка трехцветного изображения канала. ( Изображение предоставлено Невитом Дилманом по лицензии Кэла Ласелла ) .
Equalize
Теперь, когда изображения переведены в оттенки серого, они потеряли часть своей контрастности, белизны или черноты пикселей. Для повышения контрастности изображения должны быть выровнены . Это важно, потому что модель должна различать различные признаки, которые улавливаются их изменениями в контрасте.
Выравнивание изображения означает расширение распределения значений пикселей, создание более широкого диапазона белого и черного цвета изображения.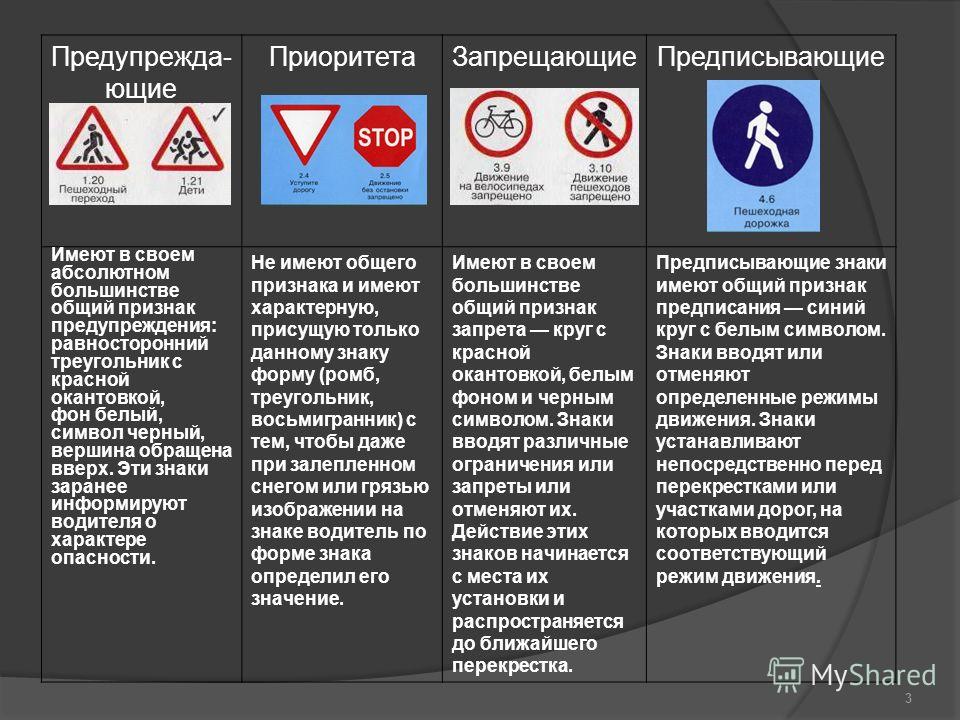
(Изображение автора)
Сверточная нейронная сеть — это класс сетей глубокого обучения, используемых для анализа визуальных образов. В данном случае он используется для поиска уникальных наборов признаков среди множества дорожных знаков.
Архитектура CNN. (Источник: https://www.mathworks.com/videos/introduction-to-deep-learning-what-are-convolutional-neural-networks—1489512765771.html)
Процесс, который он использует, подобен тому, как наши глаза и мозг сортирует все, что мы видим. Например, глядя на набор чисел, вы можете увидеть разницу между 1 и 8. 1 — это вертикальная линия, а 8 — это петля поверх другой петли. Конечно, вы на самом деле не говорите это в своей голове, потому что мы видели их так много раз, что это стало привычкой.
Как они учатся?
Для того, чтобы сверточная нейронная сеть извлекала важные особенности изображения, они используют ядер для сканирования или перемещения по изображению.
Я думаю об этом как о ваших глазах, движущихся саккадами по изображению. Они анализируют одну часть и перемещаются по горизонтали к следующему разделу, пока вы не увидите всю картину целиком.
Они анализируют одну часть и перемещаются по горизонтали к следующему разделу, пока вы не увидите всю картину целиком.
Ядра сравнивают разницу между тем, что они видят, и тем, что они ищут. Когда функция совпадает, она записывается и сохраняется в карта объектов . Эти карты признаков являются уточненными версиями исходного изображения. Они сохраняют важные черты знака и игнорируют остальные. Несколько разных ядер обрабатывают исходное изображение и извлекают различные важные функции, а затем объединяются для создания окончательного свернутого шаблона.
Выходная матрица называется Convolved Feature или Feature Map. (Источник: http://deeplearning.stanford.edu/wiki/index.php/Feature_extraction_using_convolution)
Решение переобучения
При работе с небольшим набором данных, подобным тому, который используется в модели, возникала проблема под названием возникает переоснащение . Это когда модель начинает запоминать изображений, вместо того, чтобы работать над поиском их признаков. В частности, когда модель проходит через слишком много эпох (в основном, сколько раз модель проходит через набор данных), она начинает прослушивать ввод одних узлов и игнорировать другие. Это снижает точность модели, потому что она не будет знать, как классифицировать любые новые изображения вне набора данных.
В частности, когда модель проходит через слишком много эпох (в основном, сколько раз модель проходит через набор данных), она начинает прослушивать ввод одних узлов и игнорировать другие. Это снижает точность модели, потому что она не будет знать, как классифицировать любые новые изображения вне набора данных.
Чтобы решить, Добавлен отсеваемый слой . Это простое решение этой модели. Отбрасывая случайное подмножество узлов, он предотвращает переоснащение, поскольку узлы не могут запомнить метки (поскольку существует высокая вероятность того, что узел будет отключен). Это как учитель, который зовет ребенка, который невнимателен в классе. Поставив его в неловкое положение и привлекая его внимание, он (надеюсь) сосредоточится и принесет пользу классу.
Наконец, модели предоставляется изображение дорожного знака, она проходит через сверточную нейронную сеть и выдает число, связанное с соответствующим знаком.
Когда через модель проходит следующий случайный знак…
Модель показывает случайное изображение. (Источник: https://c8.alamy.com/comp/G667W0/road-sign-speed-limit-30-kmh-zone-passau-bavaria-germany-G667W0.jpg)
(Источник: https://c8.alamy.com/comp/G667W0/road-sign-speed-limit-30-kmh-zone-passau-bavaria-germany-G667W0.jpg)
Модель предсказывает класс как [1 ], что правильно!
Класс, связанный со знаком. (Изображение автора)
Всем, кто интересуется кодом, вы можете найти его на моем GitHub, здесь!
- Изображения предварительно обработаны с помощью функции градации серого и выравнивания
- Сверточная нейронная сеть (CNN) использует ядра для извлечения признаков знака
- Особенности сравниваются с другими классифицированными изображениями, чтобы сделать прогноз
Привет, я Кель Лассел, шестнадцатилетний новатор из Общества знаний! Я увлекаюсь автономными системами, особенно беспилотными автомобилями, а также устойчивой энергетикой.
Буду признателен, если вы сможете подписаться на меня в Medium и Twitter! Кроме того, добавьте меня в LinkedIn или отправьте мне электронное письмо.
Распознавание дорожных знаков с точностью 98% с использованием глубокого обучения | Эдди Форсон
Знак «Стоп»
Это проект 2 термина 1 инженера Udacity по самоуправляемым автомобилям Nanograde . Вы можете найти весь код, связанный с этим проектом, на github . Вы также можете прочитать мой пост о проекте 1: Обнаружение полос движения с помощью Computer Vision , просто нажав на ссылку.
Вы можете найти весь код, связанный с этим проектом, на github . Вы также можете прочитать мой пост о проекте 1: Обнаружение полос движения с помощью Computer Vision , просто нажав на ссылку.
Дорожные знаки являются неотъемлемой частью нашей дорожной инфраструктуры. Они предоставляют важную информацию, а иногда и убедительные рекомендации для участников дорожного движения, что, в свою очередь, требует от них корректировки своего поведения за рулем, чтобы убедиться, что они соблюдают любые правила дорожного движения, действующие в настоящее время. Без таких полезных знаков мы, скорее всего, столкнулись бы с большим количеством аварий, так как водителям не ставили бы критических обратная связь о том, насколько быстро они могут безопасно ехать, или информирование о дорожных работах, крутом повороте или школьном переходе впереди. В наше время ежегодно на дорогах гибнет около 1,3 млн человек. Без наших дорожных знаков это число было бы намного выше.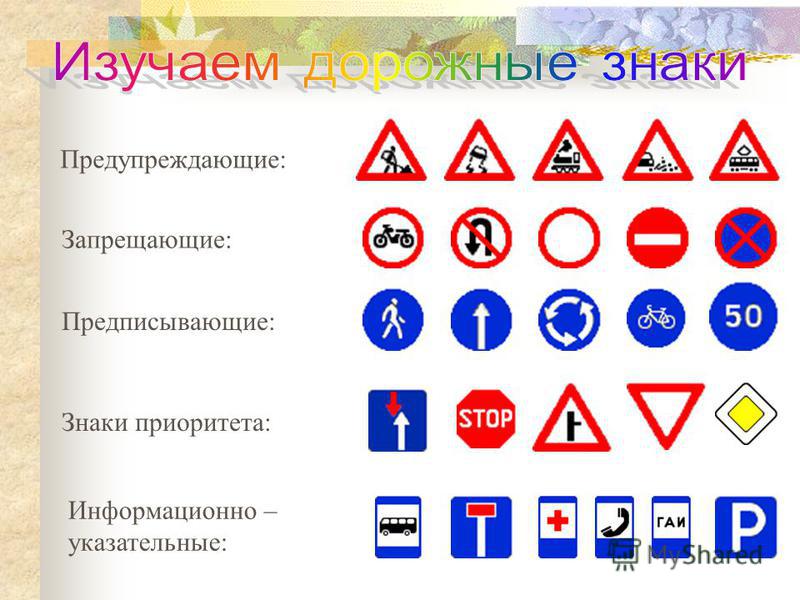
Естественно, автономные транспортные средства также должны соблюдать дорожное законодательство, поэтому распознают , а понимают дорожные знаки.
Традиционно для обнаружения и классификации дорожных знаков использовались стандартные методы компьютерного зрения, но они требовали значительного и трудоемкого ручного труда для ручной обработки важных элементов изображений. Вместо этого, применяя глубокое обучение к этой проблеме, мы создаем модель, которая надежно классифицирует дорожные знаки, учась определять наиболее подходящие функции для этой проблемы на сам . В этом посте я покажу, как мы можем создать архитектуру глубокого обучения, которая может идентифицировать дорожные знаки с точностью, близкой к 98%, на тестовом наборе.
Набор данных разделен на наборы для обучения, тестирования и проверки со следующими характеристиками:
- Изображения имеют размер 32 (ширина) x 32 (высота) x 3 (цветовые каналы RGB)
- Набор для обучения состоит из 34799 изображений
- Проверочный набор состоит из 4410 изображений
- Тестовый набор состоит из 12630 изображений
- Существует 43 класса (например, ограничение скорости 20 км/ч, въезд запрещен, ухабистая дорога и т. д.)
 д.)
д.)
Кроме того, для написания кода мы будем использовать Python 3.5 с Tensorflow.
Изображения и распространение
Ниже вы можете увидеть образец изображений из набора данных с метками, отображаемыми над рядом соответствующих изображений. Некоторые из них довольно темные, поэтому чуть позже мы постараемся улучшить контрастность.
Образец изображений тренировочного набора с метками выше
Также существует значительный дисбаланс между классами в тренировочном наборе, как показано на гистограмме ниже. Некоторые классы имеют менее 200 изображений, а другие — более 2000. Это означает, что наша модель может состоять из 9 изображений.0007 смещает в сторону чрезмерно представленных классов, особенно когда он не уверен в своих прогнозах. Позже мы увидим, как мы можем смягчить это несоответствие, используя увеличение данных.
Распределение изображений в тренировочном наборе — не совсем сбалансировано
Сначала мы применяем два этапа предварительной обработки к нашим изображениям:
Оттенки серого
Преобразуем наше 3-канальное изображение в одно изображение в градациях серого (то же самое делаем в проекте 1 — Обнаружение полосы движения — вы можете прочитать мой блог об этом ЗДЕСЬ).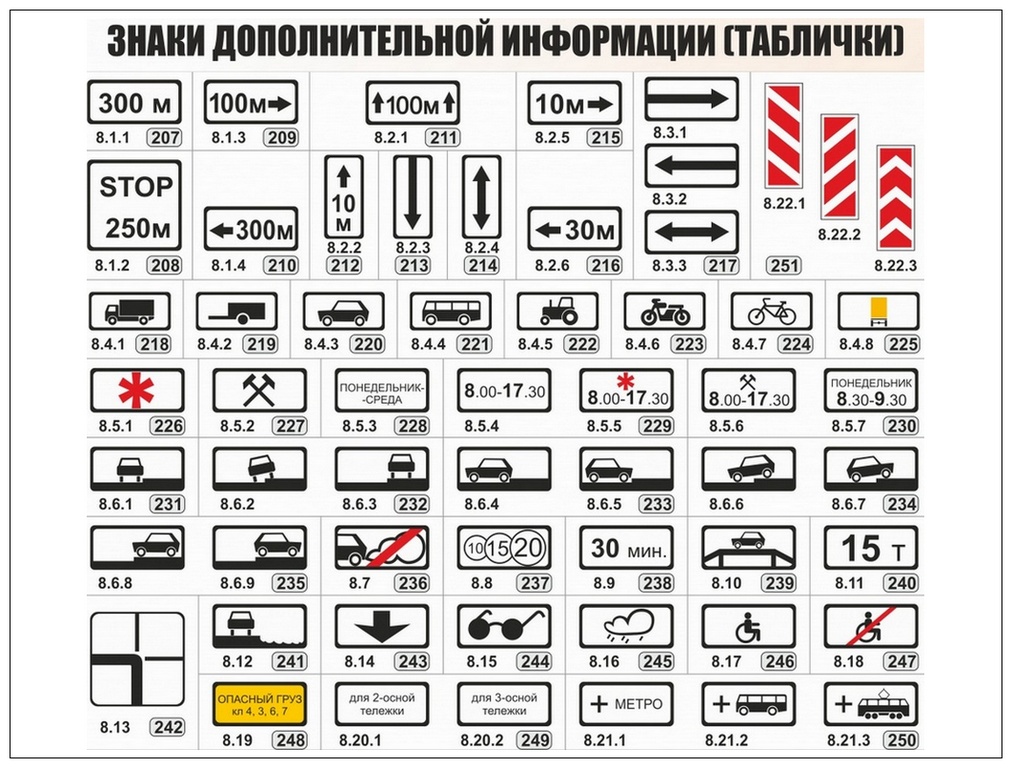
Образец изображений обучающего набора в градациях серого с метками выше
Нормализация изображения
Мы центрируем распределение набора данных изображения, вычитая каждое изображение из среднего набора данных и деля его на его стандартное отклонение. Это помогает нашей модели обрабатывать изображения единообразно. Полученные изображения выглядят следующим образом:
Нормализованные изображения — мы можем видеть, как распределяется «шум»
Предлагаемая архитектура вдохновлена статьей Яна Ле Куна о классификации дорожных знаков. Мы добавили несколько настроек и создали модульную кодовую базу, которая позволяет нам опробовать различные размеры фильтров, глубину и количество слоев свертки, а также размеры полносвязных слоев. В знак уважения к Ле Куну и с оттенком дерзости мы назвали такую сеть EdLeNet :).
В основном мы пробовали фильтры размером 5×5 и 3×3 (ядро) и начинали с глубины 32 для нашего первого сверточного слоя. Архитектура EdLeNet 3×3 показана ниже:
Архитектура EdLeNet 3×3 показана ниже:
Архитектура EdLeNet 3×3
Сеть состоит из 3 сверточных слоев — размер ядра 3×3, с удвоением глубины на следующем уровне — с использованием ReLU в качестве функции активации, за каждым из которых следует максимум 2×2 операция объединения. Последние 3 слоя полностью связаны, а последний слой дает 43 результата (общее количество возможных меток), вычисленных с использованием функции активации SoftMax. Сеть обучается с использованием мини-пакетного стохастического градиентного спуска с оптимизатором Адама. Мы создаем модульную инфраструктуру кодирования, которая позволяет нам динамически создавать наши модели, как в следующих фрагментах:
mc_3x3 = ModelConfig(EdLeNet, "EdLeNet_Norm_Grayscale_3x3_Dropout_0.50", [32, 32, 1], [3, 32, 3], [120, 84], n_classes, [0,75, 0,5])
mc_5x5 = ModelConfig(EdLeNet, "EdLeNet_Norm_Grayscale_5x5_Dropout_0,50", [32, 32, 1], [5, 32, 2], [120, 84], n_classes, [0,75, 0,5])
me_g_norm_drpt_0_50_3x3 = ModelExecutor(mc_3x3)
me_g_norm_drpt_0_50_5x5 = ModelExecutor(mc_5x5)
ModelConfig содержит информацию о модели, такую как:
- Функция модели (например,
EdLeNet) - название модели
- формат ввода (например, [32, 32, 1] для оттенков серого),
- конфигурация сверточных слоев [фильтр размер, начальная глубина, количество слоев],
- размеры полностью связанных слоев (например, [120, 84])
- количество классов
- отсев сохранить процентные значения [p-conv, p-fc]
The ModelExecutor отвечает за обучение , оценка , прогнозирование и создание визуализаций наших карт активации .
Чтобы лучше изолировать наши модели и убедиться, что все они не существуют в одном графе Tensorflow, мы используем следующую полезную конструкцию:
self.graph = tf.Graph()
с self.graph.as_default() as g :
с g.name_scope( self.model_config.name ) в качестве области видимости:
...
с tf.Session(graph = self.graph) в качестве sess:
Таким образом, мы создаем отдельные графики для каждой модели , следя за тем, чтобы наши переменные, заполнители и т. д. не смешивались. Это избавило меня от многих головных болей.
На самом деле мы начали с глубины свертки 16, но получили лучшие результаты с 32, поэтому остановились на этом значении. Мы также сравнили цветные и оттенки серого, стандартные и нормализованные изображения и увидели, что оттенки серого имеют тенденцию превосходить цвет. К сожалению, мы едва достигли 93% точности тестового набора на моделях 3×3 или 5×5, не всегда достигая этого рубежа. Более того, мы наблюдали некоторое неустойчивое поведение потерь на проверочном наборе после заданного количества эпох, что на самом деле означало, что наша модель переобучала обучающий набор, а не обобщала. Ниже вы можете увидеть некоторые из наших метрических графиков для различных конфигураций модели.
Ниже вы можете увидеть некоторые из наших метрических графиков для различных конфигураций модели.
Производительность моделей на изображениях, нормализованных по цвету Производительность моделей на нормализованных изображениях в градациях серого
Чтобы повысить надежность модели, мы обратились к отсеву, который представляет собой форму регуляризации, при которой веса сохраняются с вероятностью p : таким образом, неучтенные веса «отбрасываются». ». Это предотвращает переоснащение модели. Dropout был представлен Джеффри Хинтоном, пионером в области глубокого обучения. Статья его группы по этой теме обязательна к прочтению, чтобы лучше понять мотивы авторов. Есть также увлекательная параллель с биологией и эволюцией.
В работе авторы применяют разную степень отсева в зависимости от типа слоя. Поэтому я решил применить аналогичный подход, определив два уровня отсева: один для сверточных слоев, другой для полносвязных слоев:
p-conv: вероятность сохранения веса в сверточном слое
p-fc: вероятность сохранения веса в полносвязный слой
Более того, авторы постепенно принимали более агрессивные (т.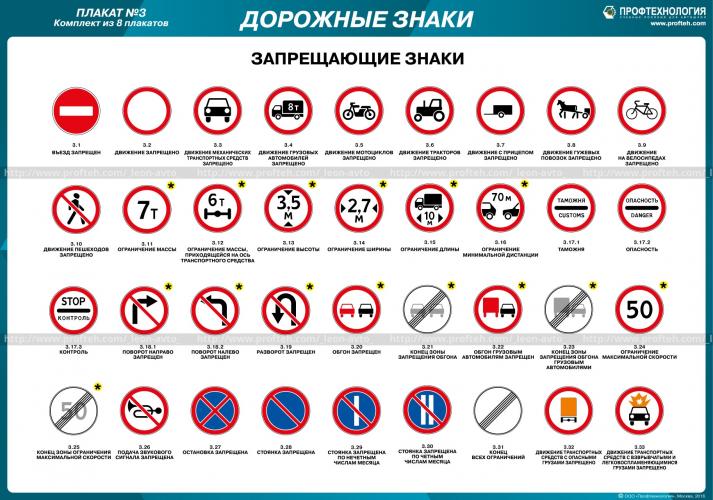 е. более низкие) значения отсева по мере углубления в сеть. Поэтому я и решил:
е. более низкие) значения отсева по мере углубления в сеть. Поэтому я и решил:
p-conv >= p-fc
то есть мы будем сохранять веса с большей или равной вероятностью в сверточных слоях, чем полносвязные. Это объясняется тем, что мы относимся к сети как к воронке и, следовательно, хотим постепенно ужесточать ее по мере продвижения вглубь слоев: мы не хотим с самого начала отбрасывать слишком много информации, поскольку часть ее быть чрезвычайно ценным. Кроме того, поскольку мы применяем MaxPooling в сверточных слоях, мы уже теряем немного информации.
Мы пробовали разные параметры, но в конечном итоге остановились на p-conv=0,75 и p-fc=0,5 , что позволило нам достичь точности тестового набора 97,55% на нормализованных изображениях в градациях серого с моделью 3×3. Интересно, что мы достигли точности более 98,3% на проверочном наборе:
Training EdLeNet_Norm_Grayscale_3x3_Dropout_0,50 [epochs=100, batch_size=512]...
[1] total=5,222 с | поезд: время = 3,139 с, потеря = 3,4993, акк = 0,1047 | знач.
[10] всего=5,190 с | поезд: время = 3,122 с, потеря = 0,2589, акк = 0,9360 | val: time=2.067s, loss=0.3260, acc=0.8973
...
[90] total=5.193s | поезд: время = 3,120 с, потеря = 0,0006, акк = 0,9999 | val: time=2,074 с, loss=0,0747, acc=0,9841
[100] total=5,191 с | поезд: время = 3,123 с, потеря = 0,0004, акк = 1,0000 | val: time=2.068s, loss=0.0849, acc=0.9832, acc=0.9755
 : время=2,083 с, потеря=3,5613, акк=0,1007
: время=2,083 с, потеря=3,5613, акк=0,1007 Производительность моделей на нормализованных изображениях в градациях серого после введения Dropout
Графики выше показывают, что модель является гладкой , в отличие от некоторых графиков выше. Мы уже достигли цели, обеспечив точность более 93 % на тестовом наборе, но можем ли мы добиться большего? Помните, что некоторые изображения были размытыми, а распределение изображений по классам было очень неравномерным. Ниже мы рассмотрим дополнительные методы, которые мы использовали для решения каждой проблемы.
Выравнивание гистограммы — это технология компьютерного зрения, используемая для повышения контрастности изображений. Поскольку некоторые из наших изображений имеют низкую контрастность (размытые, темные), мы улучшим видимость, применив функцию OpenCV Contrast Limiting Adaptive Histogram Equalization (она же CLAHE).
Поскольку некоторые из наших изображений имеют низкую контрастность (размытые, темные), мы улучшим видимость, применив функцию OpenCV Contrast Limiting Adaptive Histogram Equalization (она же CLAHE).
Мы еще раз пробуем различные конфигурации и находим наилучшие результаты с точностью теста 97,75% на модели 3×3, используя следующие значения отсева: p-conv=0,6 , p-fc=0,5 .
Обучение EdLeNet_Grayscale_CLAHE_Norm_Take-2_3x3_Dropout_0.50 [эпохи = 500, batch_size = 512]... [1] всего = 5,194 с | поезд: время = 3,137 с, потеря = 3,6254, акк = 0,0662 | val: time=2,058 с, loss=3,6405, acc=0,0655
[10] total=5,155 с | поезд: время = 3,115 с, потеря = 0,8645, акк = 0,7121 | val: time=2.040s, loss=0.9159, acc=0.6819
...
[480] total=5.149s | поезд: время = 3,106 с, потеря = 0,0009, акк = 0,9998 | val: time=2,042 с, loss=0,0355, acc=0,9884
[490] total=5,148 с | поезд: время = 3,106 с, потеря = 0,0007, акк = 0,9998 | val: time=2,042 с, loss=0,0390, acc=0,9884
[500] total=5,148 с | поезд: время = 3,104 с, потеря = 0,0006, акк = 0,9999 | val: time=2.
 044s, loss=0.0420, acc=0.9862 0,9775
044s, loss=0.0420, acc=0.9862 0,9775 Ниже приведены графики предыдущих прогонов, в которых мы также тестировали модель 5×5, более 220 эпох. Здесь мы видим гораздо более гладкую кривую, что подтверждает нашу интуицию о том, что имеющаяся у нас модель более стабильна.
Производительность моделей на изображениях, выровненных в оттенках серого, с отсевом
Мы определили 269 изображений, которые модель не смогла идентифицировать правильно. Ниже мы показываем 10 из них, выбранных случайным образом, чтобы предположить, почему модель была ошибочной.
Пример из 10 изображений, где наша модель ошиблась в предсказаниях
Некоторые изображения очень размыты, несмотря на нашу гистограмму, а другие кажутся искаженными. Вероятно, у нас недостаточно примеров таких изображений в нашем тестовом наборе, чтобы прогнозы нашей модели улучшились. Кроме того, в то время как 9Точность теста 7,75% — это очень хорошо, но у нас есть еще один козырь в рукаве: увеличение данных.
Ранее мы заметили, что данные представляют вопиющий дисбаланс между 43 классами. Тем не менее, это не кажется серьезной проблемой, поскольку мы можем достичь очень высокой точности, несмотря на дисбаланс классов. Мы также заметили, что некоторые изображения в тестовом наборе искажены. Поэтому мы собираемся использовать методы увеличения данных, чтобы попытаться:
Тем не менее, это не кажется серьезной проблемой, поскольку мы можем достичь очень высокой точности, несмотря на дисбаланс классов. Мы также заметили, что некоторые изображения в тестовом наборе искажены. Поэтому мы собираемся использовать методы увеличения данных, чтобы попытаться:
- Расширить набор данных и предоставить дополнительные изображения при различных настройках освещения и ориентации
- Улучшение способности модели становиться более универсальной
- Повышение точности тестирования и проверки, особенно на искаженных изображениях
Мы используем изящную библиотеку под названием imgaug для создания наших дополнений. В основном мы применяем аффинные преобразования для увеличения изображений. Наш код выглядит следующим образом:
def augment_imgs(imgs, p):
"""
Выполняет набор аугментаций с вероятностью p
"""
augs = iaa.SomeOf((2, 4),
[
iaa.Crop(px=(0, 4)), # обрезаем изображения с каждой стороны на 0–4 пикселя (выбирается случайным образом)
iaa.
iaa.Affine(translate_percent={"x": (-0,2, 0,2), " y": (-0.2, 0.2)}),
iaa.Affine(rotate=(-45, 45)), # повернуть на -45 до +45 градусов)
iaa.Affine(shear=(-10, 10) ) # сдвиг от -10 до +10 градусов
])
seq = iaa.Sequential([iaa.Sometimes(p, augs)])
return seq.augment_images(imgs)
 Affine(scale={"x": (0,8, 1,2), "y": (0,8, 1,2)}),
Affine(scale={"x": (0,8, 1,2), "y": (0,8, 1,2)}), Хотя дисбаланс классов, вероятно, вызывает некоторое смещение в модели мы решили не рассматривать это на данном этапе, так как это приведет к значительному увеличению нашего набора данных и увеличению времени обучения (у нас не так много времени, чтобы тратить на обучение на этом этапе). Вместо этого мы решили увеличить каждый класс на 10%. Наш новый набор данных выглядит следующим образом.
Sample Of Augmented Images
Распределение изображений, конечно, существенно не меняется, но мы применяем этапы предварительной обработки изображений в оттенках серого, выравнивание гистограммы и нормализацию. Мы тренируемся на 2000 эпох с отсевом ( p-conv=0,6 , p-fc=0,5 ) и достигаем 97,86% точности на тестовом наборе:
[EdLeNet] Построение нейронной сети [conv Layers=3, conv filter size=3, conv start depth=32, fc layer=2]
Обучение EdLeNet_Augs_Grayscale_CLAHE_Norm_Take4_Bis_3x3_Dropout_0.
[1] всего=5,824 с | поезд: время = 3,594 с, потеря = 3,6283, акк = 0,0797 | val: time=2.231s, loss=3.6463, acc=0.0687
...
[1970] total=5.627s | поезд: время = 3,408 с, потеря = 0,0525, акк = 0,9870 | val: time=2,219 с, loss=0,0315, acc=0,9914
[1980] total=5,627 с | поезд: время = 3,409 с, потеря = 0,0530, акк = 0,9862 | val: time=2,218 с, loss=0,0309, acc=0,9902
[1990] total=5,628 с | поезд: время = 3,412 с, потеря = 0,0521, акк = 0,9869 | val: time=2,216 с, loss=0,0302, acc=0,9900
[2000] total=5,632 с | поезд: время = 3,415 с, потеря = 0,0521, акк = 0,9869 | val: time=2.217s, loss=0.0311, acc=0.9902
Model ./models/EdLeNet_Augs_Grayscale_CLAHE_Norm_Take4_Bis_3x3_Dropout_0.50.chkpt saved[EdLeNet_Augs_Grayscale_CLAHE_Norm_Take4_Bis_3x3_Dropout_0.50 - Test Set] time=0.678s, loss=0.0842, acc=0.9786
 50 [epochs=2000, batch_size=512]...
50 [epochs=2000, batch_size=512]... Это наше лучшее выступление!!!
Neural Network Celebration
Но … если вы посмотрите на метрику потерь на тренировочном наборе, вы увидите, что при 0,0521 у нас, скорее всего, еще есть пространство для маневра. Мы планируем тренироваться еще несколько эпох и сообщим о наших новых результатах в будущем.
Мы планируем тренироваться еще несколько эпох и сообщим о наших новых результатах в будущем.
Мы решили протестировать нашу модель и на новых изображениях, чтобы убедиться, что она действительно обобщается не только на дорожные знаки в нашем исходном наборе данных. Поэтому мы загрузили пять новых изображений и отправили их в нашу модель для прогнозов.
Скачать 5 новых дорожных знаков — цвет
Основная правда для изображений следующая:
['Ограничение скорости (120км/ч)',
'Основная дорога',
'Нет транспортных средств',
'Дорожные работы',
«Запрещено движение транспортных средств полной массой более 3,5 метрических тонн»]
Изображения были выбраны по следующим причинам:
- Они представляют собой различные дорожные знаки, которые мы в настоящее время классифицируем
- Они различаются по форме и цвету
- Они находятся в разных условиях освещения (четвертое имеет отражение солнечного света)
- Они находятся в разных ориентациях (третье наклонено)
- У них разный фон
- Последнее изображение на самом деле является дизайном, а не реальным изображением, и мы хотели протестировать модель на нем
- Некоторые из них относятся к недопредставленным классам
Первым шагом, который мы предприняли, было применение того же CLAHE к этим новым изображениям, в результате чего получилось следующее:
Загрузите 5 новых дорожных знаков — оттенки серого CLAHE
100% на новых изображениях. На исходном тестовом наборе мы достигли точности 97,86%. Мы могли бы изучить размытие/искажение наших новых изображений или изменение контраста, чтобы увидеть, как модель обрабатывает эти изменения в будущем.
На исходном тестовом наборе мы достигли точности 97,86%. Мы могли бы изучить размытие/искажение наших новых изображений или изменение контраста, чтобы увидеть, как модель обрабатывает эти изменения в будущем.
new_img_grayscale_norm_pred_acc = np.sum(new_img_lbs == preds) / len(preds)
print("[Нормализованные оттенки серого] Точность прогнозирования для новых изображений: {0}%".format(new_img_grayscale_norm_pred_acc * 100))
...
[Нормализованные оттенки серого] Точность прогнозирования для новых изображений: 100,0%
Мы также показываем 5 лучших вероятностей SoftMax, рассчитанных для каждого изображения, с зеленой полосой, показывающей основную правду. Мы ясно видим, что наша модель вполне уверена в своих предсказаниях. В худшем случае (последнее изображение) второй наиболее вероятный прогноз имеет вероятность около 0,1%. На самом деле наша модель больше всего борется с последним изображением, которое, я считаю, на самом деле является дизайном, а даже не реальным изображением.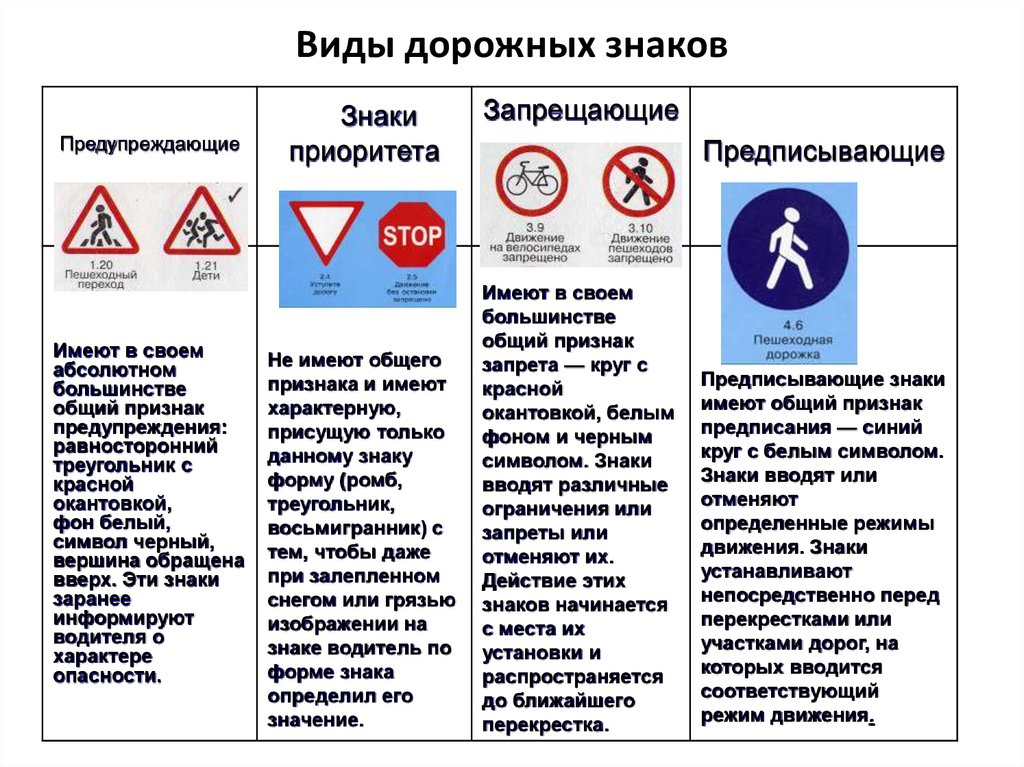 В целом, мы разработали сильную модель!
В целом, мы разработали сильную модель!
Визуализация 5 лучших прогнозов модели
Ниже мы показываем результаты, полученные каждым сверточным слоем (до максимального объединения), в результате чего получаются 3 карты активации.
Уровень 1
Мы видим, что сеть сильно фокусируется на краях круга и каким-то образом на грузовике. Фон в основном игнорируется.
Слой 2
Карта активации второго сверточного слоя
Довольно сложно определить, на чем фокусируется сеть в слое 2, но кажется, что она «активируется» по краям круга и в середине, где появляется грузовик .
Уровень 3
Эту карту активации тоже сложно расшифровать… Но кажется, что сеть снова реагирует на стимулы на краях и в середине.
Мы рассмотрели, как можно использовать глубокое обучение для высокоточной классификации дорожных знаков, применяя различные методы предварительной обработки и регуляризации (например, отсев) и пробуя различные архитектуры моделей. Мы создали легко настраиваемый код и разработали гибкий способ оценки нескольких архитектур. Наша модель приблизилась к 9Точность 8% на тестовом наборе, достижение 99% на проверочном наборе.
Лично мне этот проект очень понравился, и я получил практический опыт использования Tensorflow, matplotlib и исследования архитектур искусственных нейронных сетей. Более того, я углубился в некоторые основополагающие статьи в этой области, которые укрепили мое понимание и, что более важно, улучшили мою интуицию о глубоком обучении.
Я считаю, что в будущем более высокая точность может быть достигнута путем применения дополнительных методов регуляризации, таких как пакетная нормализация, а также путем внедрения более современных архитектур, таких как начальный модуль GoogLeNet, ResNet или Xception.
Спасибо, что прочитали этот пост. Я надеюсь, что вы сочли полезным. Сейчас я создаю новый стартап под названием EnVsion ! В EnVsion мы создаем центральный репозиторий для UX-исследователей и групп разработчиков, чтобы они могли раскрыть идеи из их видео с интервью с пользователями.